在開始探討 Transformer 模型架構之前,先來說明一下「神經序列轉導模型 (Neural Sequence Transduction Model)」這一個老頭之前不是很熟悉的詞彙。
轉導 (Transduction,註一) 這個字的原始意義是「轉換某一物體至另外一種形式」,在自然語言處理的領域中,常見的「序列轉導 (Sequence Transduction)」指的是將某一段文字或語音 (即是文字語音序列) 轉換為另一種形式的表示法,像是「翻譯 (Translation)」就是典型的序列轉導行為。因此所謂的「神經序列轉導模型」,即是一個深度神經網路模型(DNN 模型)其執行序列轉導的工作。
「編碼器/解碼器 (Encoder/Decoder)」結構是最常使用也最有效的神經序列轉導模型。Transformer 基本上也是要解決序列轉導問題的,所以它也使用了編碼器/解碼器模型結構,下圖即為 Transformer 的最高階的結構圖(註二):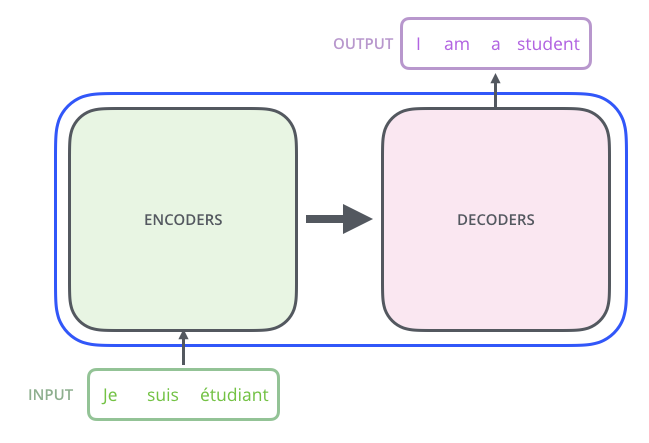
編碼器包含 6 個完全相同的神經網路層 (layer),每一個網路層包含了 2 個子層 (sub-layer),第一個子層是 multi-head self-attention 層,第二個子層是 positionwise fully connected feed-forward 層。每一個子層皆實作 residual connection 並於子層輸出處執行正規化 (normalization) 處理。編碼器的結構如下圖: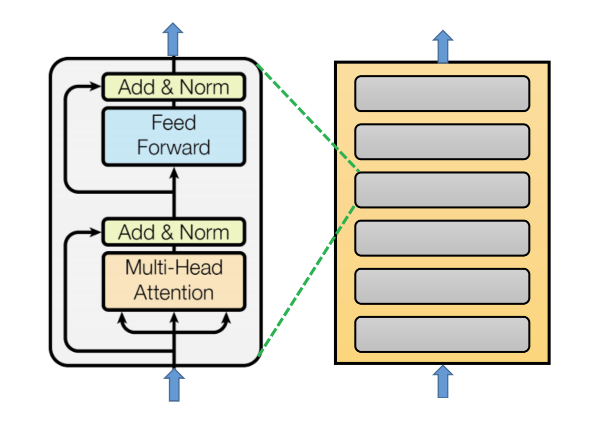
用數學式來看,每一個網路層可以表示為:
Input: x
1st Sublayer Output:
2nd Sublayer Output:
何謂 multi-head?何謂 positionwise?在論文稍後有詳細的說明。
解碼器也同樣包含了 6 個相同的神經網路層,每一個網路層含有 3 個子層,由下到上分別是
Masked Multi-Head Self-Attention
Multi-Head Attention
Positionwise Fully Connected Feed-Forward
每一個子層也實作 residual connection 及正規化處理。解碼器的結構如下圖: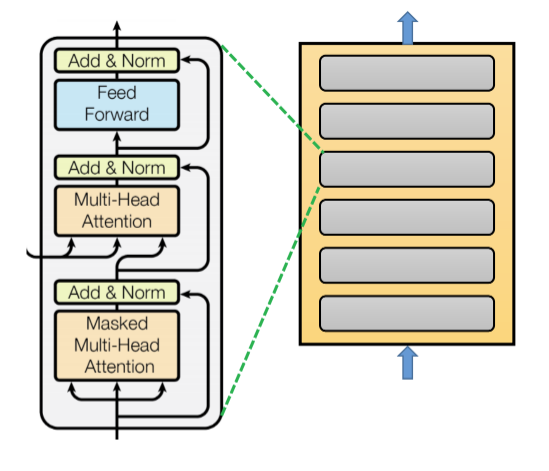
要使用 Masked Multi-Head Self-Attention 的理由是:確保在計算第 i 個解碼器輸出時,僅用到 i 之前的輸出值。
第二個子層 Multi-Head Attention,是以「第一個子層的輸出」和「編碼器的輸出」執行 Attention 計算。
結合編碼器及解碼器,並分別在其輸入前加上 Embedding & Positional Encoding,並在解碼器的輸出處加上 Linear 層及 Softmax 層,如此便是 Transformer 的全貌了。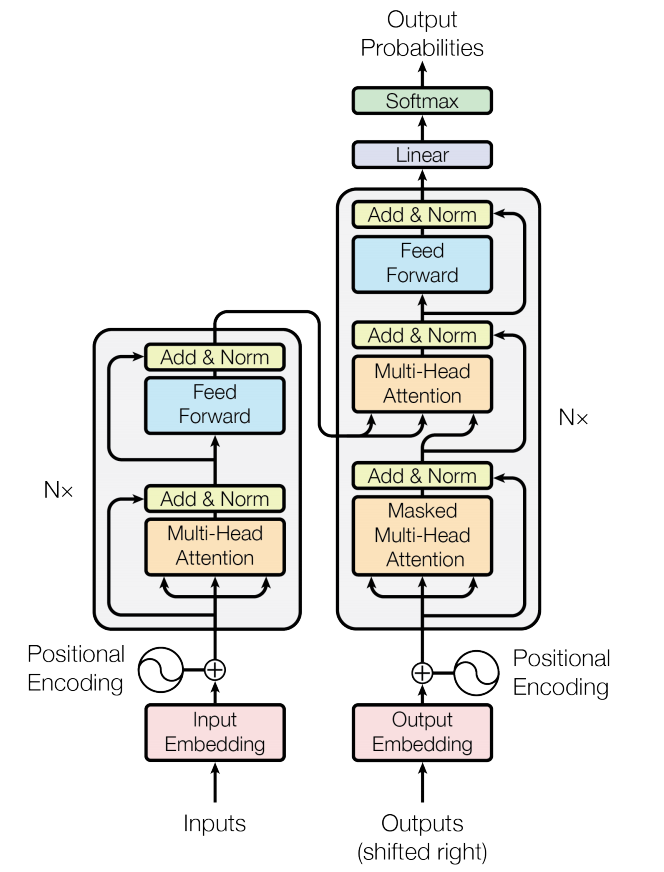
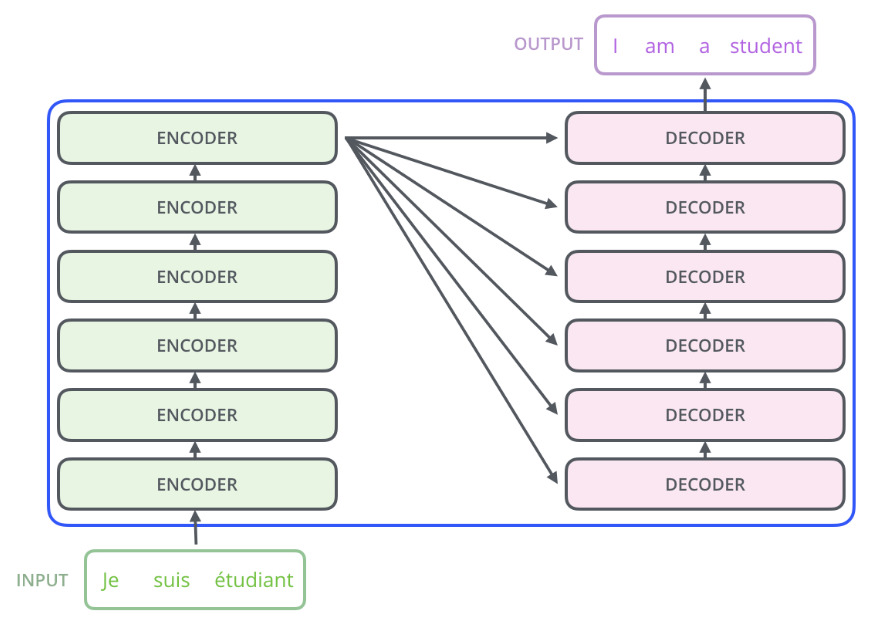
而在這個結構之下,Transformer 是怎麼運作的?舉個例子,如下圖(註二),這是一個由法文翻譯為英文的 Transformer,從編碼器端輸入一句法文「je suis etudiant」,從解碼器端則輸出翻譯出的英文「I am a student」。整個流程主的步驟是:
Step 1:整句法文「je suis etudiant」做為編碼器的輸入,編碼器一次處理整個句子,產生輸出 X。
Step 2:解碼器以 X 及空序列做為其輸入,產生第一個輸出 I。
Step 3:解碼器以 X 及 I 做為其輸入,產生第二個輸出 am。
Step 4:解碼器以 X 及 I am 做為其輸入,產生第三個輸出 a。
Step 5:解碼器以 X 及 I am a 做為其輸入,產生第四個輸出 student。
Step 6:解碼器以 X 及 I am a student 做為其輸入,產生第五個輸出 <end of sentence>。
(註一:在 Machine Learning Mastery 網站上有一篇介紹 Transduction 的文章「Gentle Introduction to Transduction in Machine Learning」) 大家可以參考)
(註二:源自 Jay Alammar 的《The Illustrated Transformer》 )


 iThome鐵人賽
iThome鐵人賽